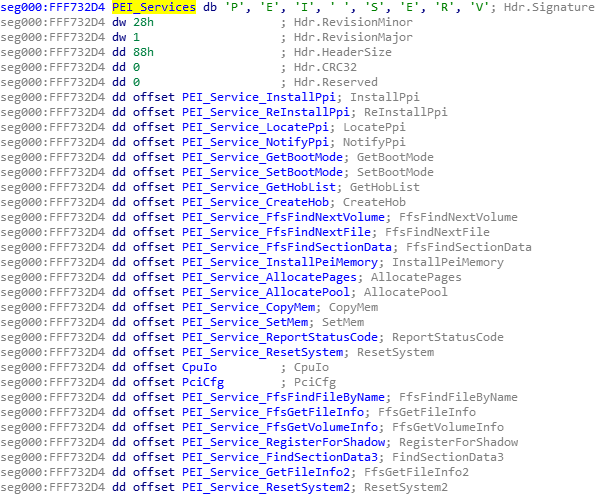
In mid-November, a little over two four nine months ago, I wrote Part 1 and Part 2 of my series of articles about exploiting the Intel ME. I also said I’d write Part 3 by the end of the week. Oops.
Unfortunately, a lot of stuff happened, life caught up to me, then I became busy with another hobby, and then extremely busy with starting a new business of mine (a D&D Game hosting service for Foundry Virtual Tabletop). I’ve wanted to finish my third article for a while now, and I’m taking the time to do it today, though it might not be as verbose as usual because my time is very limited lately (also, it’s been so long, my memory of everything I did isn’t as fresh as I’d want it to be). Me finding a new hobby around D&D gaming and now working on my new business venture is what prompted me to start these articles in the first place, since I knew I wouldn’t have any more time to actually finish this project I started so long ago, so here’s everything I did so far, maybe someone else will finish it.
The big question when it comes to getting code execution on the Intel ME might be “Why?” Well, I thought it would be fun to try and create a keylogger that runs directly on the ME. Not many people know this, but one of the first things I did as a script kiddie was play around with keyloggers. While they have the “steal your friend’s passwords” use, I had one installed on my own PC and it was extremely useful for recovering content I’d write (before text editors or email apps had auto-save features) or using it as a log of what I did and when I did it.
How to keylog? The basics.
How can we use the ME to keylog a machine? The answer is simple, we hijack the USB controller; hence the title of this article!
We need to go back to the PT research Black Hat slides, but not the same ones I mentioned in my previous articles, not the Black Hat Europe 2017 slides, but the Black Hat Asia 2019 ones about Intel VISA (Visualization of Internal Signals Architecture).
In it, Mark Ermolov and Maxim Goryachi talk about the IOSF, the Intel On-chip System Fabric (I briefly mentioned it in Part 2) and explain that it’s used to interconnect all the IP units (USB controller, Graphics card, SATA controller, Audio controller, Ethernet adapter, etc..) of the PCH to each other.
I’m fairly certain (though not 100% sure) that the way it works is that everything is connected to the IOSF, and the IOSF decides which IP unit actually appears to be connected to what, based on their access permissions. So when you talk over the PCI bus to a device, the PCI bridge will simply proxy everything to the IOSF Primary by specifying the Dest ID based on the PCI BDF (Bus/Device/Function), so it uses the IOSF bus internally instead of an actual PCI bus. The whole thing is managed with a permission/identification system called SAI which allows the IOSF to filter the requests and redirect them accordingly.
See the following interesting tidbits from PT’s slides (IP in this context means an Intellectual Property unit):


That’s for the IOSF Primary, but there’s also the IOSF Sideband. My understanding of it is that everything is connected to the IOSF via the sideband too and it can be used to bypass the entire bus routes by specifying what device you want to communicate with. I’m not entirely sure yet on the exact differences between the IOSF primary and the sideband, but that’s what we used before in order to enable Red JTAG Unlock on the Dfx-Aggregator device and enable DCI on the DCI device.

Knowing all that, we can start to poke at the USB device using its Sideband channel.
Woah there, slow down!
Ok! Maybe we can’t start right away, because we have no idea how to do any of that, just yet. I don’t want to explain however how I got to that point because it’s long and boring. The summary though is that I dumped all the addresses from the MMIO ranges that the BUP module had access to, then tried to find some patterns there. I did find a table that contained addresses, and after a while, with a lot of trial and error and some poking at the BUP code, I figured that at address 0xF00A9000 was the “ATT Bridge” that PT mentioned which has tables for mapping local addresses to a sideband channel. I have also figured out (with help from others, as always) that the format of those configuration channels are :
| Offset | Size | Bits | Description |
| 0x00 | 4 | MMIO address used to access the SB channel | |
| 0x04 | 4 | Size of the SB window | |
| 0x08 | 4 | Control flags (bit 0= enabled, bit 1= locked) | |
| 0x0C | 12 | unused as far as I can see | |
| 0x18 | 4 | Sideband channel | |
| 0-7 | Sideband Port ID (0x84 = Dfx-Agg device) | ||
| 8-15 | Read opcode (6 = Read Private Configuration Space) | ||
| 16-23 | Write opcode (7 = Read Private Configuration Space) | ||
| 24-27 | BAR | ||
| 28 | posted | ||
| 29 | not sure | ||
| 0x1C | 4 | Sideband access type | |
| 0-2 | Function ID | ||
| 3-7 | Device ID | ||
| 8-15 | Root space (0 = Main CPU, 1 = CSME) |
I’ve already explained the format of the ‘Sideband channel’ in my Part 2 article, that was where the 0x70684 magic value was which was used for accessing the Dfx-Agg device (port 0x84, read opcode 6, write opcode 7).
We are also going to need to know what the Port ID for the USB controller (called the XHCI controller) is. For Skylake, it’s easy, it was in the datasheet I mentioned before, but for Apollolake, I had to brute force all the ports and try to figure out what their content was for. Eventually, I had port 0xa2 for APL, and 0xe6 for SKL.
Another thing to note, the main CPU has to be booted for this to work, otherwise the XHCI controller is not powered and doesn’t respond to any requests. I had also spent a lot of time understanding and poking at the memory segments/paging to understand how the CSME memory space is organized. I won’t bore you with that either, but I wrote scripts to dump the segment list and paging information, you will find all of that in my ipclib.
IPCLib?
That’s a little python library I wrote which uses OpenIPC’s ipccli python module. Any time I needed to do something more than once, I wrote it there and used it. There are all sorts of useful functions, but zero documentation. You can call ‘execute_asm‘ and give it a list of instructions and it will run them, you can use ‘print_registers‘ to have it dump all of your registers, use ‘step‘ or ‘stepOver‘ or ‘goUntil‘ to do step by step debugging of the CPU (because the native stepping functions in ipccli had some quirks that made it not work as expected). You should also be using the ‘asm‘ function to decompile code, because if you use OpenIPC’s asm function directly, it will corrupt the registers and things will break when you step back into the code, so I had to back them up before decompiling and restore the registers before continuing. It also has all the bruteforcing methods I wrote as well as the XHCI Controller implementation, but more on that later.
I am releasing the code to ipclib under the GPL license and it’s available on my github. Releasing this is a big part of today’s article as well.
The best thing to do with it though is to actually read the various functions available, they can be self explanatory (like ‘print_registers‘ or ‘escalate_to_ring0‘, or ‘malloc‘ for example), or can be more obscure. Some of the functions won’t make any sense (like ‘v3_resume‘ for my 3rd attempt at resuming ME execution after the exploit runs) because I used them just to test something at some point and they’ll be completely useless to everyone but I’m not bothering on cleaning up the code or documenting it (lack of time, remember?)… I guess that just makes things more fun for reverse engineers 🙂
Also note that while I’ve explained above how to access the IOSF Sideband mapping in the ATT gasket, there’s also a DRAM mapping region which I won’t bother to explain but in ipclib, you will see it be used, so we can map any DRAM region to access it from the ME, which is pretty cool.
The XHCI Controller
Back to the meat of the subject, the XHCI Controller. Can I hijack it? It turns out the answer is yes… and no… It depends on a few things.
On Apollolake, it’s easy, I can use the sideband channel to read from the USB controller, and write to its registers. I had to read the XHCI specification and write my own XHCI controller driver in python, basing it off the coreboot and seabios implementations. I can do things such as :
- Reset/Initialize the USB controller
- Enumerate the devices
- Send commands and receives events from the USB controller
- Assign a device ID for the usb devices
I didn’t get further than that due to lack of time, but it’s a simple matter of finishing my XHCI Controller (basically rewriting the coreboot implementation in python), then I would have been able to even transfer files from/to the USB flash drives I had connected to the Gigabyte Brix for testing. It’s not much, but at least I was able to see which ones were USB 2 or USB 3 and communicate with them.
On Skylake unfortunately, I was unable to access the XHCI controller via the sideband. You can see my discussion about this on https://github.com/ptresearch/IntelTXE-PoC/issues/12
As you could read from the issue linked to above, I originally thought that it was the EPMASK that was preventing access to the XHCI controller by entirely disabling the endpoint :
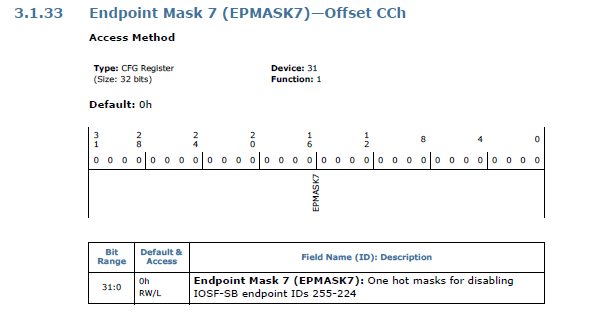
Eventually, I figured that it was the CP, RAC and WAC access policies that were preventing the ME from communicating with the XHCI controller via the Sideband channel.

The CP, RAC and WAC are registers that define which SAI agents (which other IP units connected to the IOSF fabric) can access the registers of the sideband. CP is “Control Policy” and defines which SAI agents can read and write the CP, RAC and WAC registers themselves. RAC is “Read Access Control” and defines which SAI agents can read the registers of the unit, while WAC is “Write Access Control” and defines which agents can write to its registers.
And the reason I know that the access control is based on the CP, RAC and WAC rather than EPMASK is because when I try to read the registers of the controller using the JTAG interface (the Tap2IOSF stateport device), it works, but more than that, when trying to read the private configuration space, I’m able to read most of it, but a small region is simply not responding to my reads, indicating that access is blocked for a specific portion of the registers, and that means those are the CP, RAC and WAC registers. It also means that while the Tap2IOSF device has read/write access, it does not have CP access which is why it can’t read those access control registers.
Since we now know that the CSME doesn’t have CP or RAC access to the XHCI Controller registers, here’s a question, does it have write access? And the answer is YES! It’s funny, while we can’t read any of the registers, we can write to them without problem (which re-confirms the assumption about CP/RAC/WAC). It’s unfortunate though that PT were mistaken when they said the CSME has a full privileged SAI to access all the devices, it’s just that its SAI agent value has broader permissions, but as we can see for Skylake, the USB controller doesn’t let the ME read any of its registers, so we can’t send commands and receive events from it. To be fair though, I think the ME does have full privileged access but I think the ME removes some of its own privileges during boot, so PT were probably right anyway. It’s unfortunately the same situation with the SATA controller too, and it might be affecting other devices as well.
How to keylog, really.
Now that we can talk to the USB controller, how can we create our keylogger? That’s of course, for Apollolake, since Skylake is challenging in a different way.
First of all, when the main CPU sets the BARs and configures the XHCI Controller’s PCI configuration space, the ME can store those values, change them so the ME is actually the one communicating with the controller and it can proxy all the commands and data back and forth between the main CPU and the controller. Basically, a Man-in-the-middle attack on the USB controller, allowing it to both monitor everything that passes through USB (including keyboard and mouse of course) and store it elsewhere (perhaps on the hard drive itself since it should be relatively easy to do the same thing with the SATA controller and control it from the ME… or it could save it in RAM and periodically send it over the network since the ME also has access to the ethernet adapter). It could also be used to emulate keystrokes, which could be fun.
To explain that further, basically once the OS has booted, it configures the XHCI Controller on the PCI bus so that it can send commands to it though a command buffer by writing the commands to an area of the RAM, and when an event happens (data becomes available) from USB, the event is written in the RAM by the XHCI controller so the main CPU can read it though the event ring, and then it can read the data transferred to/from USB through the transfer ring.
See this image (From page 57 of Intels’ xHCI document) which shows the general architecture of the communication with the XHCI controller :
As you can see the Cmd Ring, Event Ring, Transfer Ring and all the Data Buffers are in the Host Memory, and the configuration of where they are is stored in the MMIO Space that is set in the PCI configuration space.
To hijack the USB, the CSME just needs to wait for the OS to boot, then it would change the configuration from the MMIO registers that the OS has set in such a way that sending commands does not do anything anymore (since the xHCI controller isn’t looking at that Cmd Ring anymore), but instead, the CSME would be the one reading the RAM, deciding if it wants to forward the command, modify it, save information from it, etc.. then writing the same (or modified) command in the actual Cmd Ring that the xHCI controller is listening to. When an event or data is received, The CSME would copy that data over to the Event Ring or Data Ring that the OS has set up. And there you go, we have full control over the USB interface with our CSME in the middle attack!
Here’s a badly drawn (my art skills are amazing!) diagram showing how the Man in the Middle attack works :
An alternative solution would be not to change any of the PCI configuration, but simply look for the command, event and transfer rings of the XHCI controller as set up by the main OS and monitor their contents directly since we can map any DRAM region to access it from the ME. By doing that, we would have less of an impact on the main CPU, with no risk of potentially decreasing the performance (especially when it comes to USB flash drive transfers), but we’d need to be able to receive interrupts from the controller. I’m not so good when it comes to interrupts, so I don’t know how that would work.
How about Skylake ?
Skylake (and Kabylake as well actually) are different because we can’t read the registers from the XHCI controller, so we can’t save the actual RAM addresses that the Host is sending command to, but since we can write to the MMIO registers, we can still do a lot of mischief. I actually had a little fun resetting the controller while the OS is booted and it caused all USB devices to stop working. I also did that on the SATA controller and all hard drives stopped responding… a lot of fun, and more of a malicious virus behavior than my original keylogger plan.
Note that I never got around to actually writing the code as a binary to run on the ME, which was ultimately my plan, which is why I’m mentioning the issue with SKL/KBL. But if I were to do the keylogger entirely using IPC commands over JTAG, then it wouldn’t be a problem since we can read from the XHCI controller via Tap2IOSF. The code I wrote in ipclib for it was mostly just a playground to test and see how it could be done from within the ME itself and I’ve confirmed that anything I’ve done so far would work exactly the same if it were executed from the ME firmware itself.
But all hope isn’t lost for getting it to work on Skylake, there are a few options still available :
- We could try to find who sets the initial permissions on the USB controller as it boots (is it hardcoded in the silicon? is the ME itself setting it when it turns the power on? Or perhaps it’s configured in the PMC (Power Management Controller) or some other device) and it can be configured to give full access to the CSME’s SAI.
- Instead of using the sideband channel, we could use the IOSF Primary bus directly, there’s a possibility that we could have access to it fully that.
- We can perhaps read the registers by using the Tap2IOSF device if the ME is able to communicate with it directly and ask it to read the IOSF for us, emulating the commands sent via JTAG, which do actually work for reading even on SKL and KBL.
- We can maybe scan the RAM to find the command/event/transfer ring buffers that the OS allocated and use them without having to read their values from the PCI configuration space
- Maybe map those registers to another address by using another SAI, perhaps a subsystem of the ME or another device could have access to it (isn’t DMA doable from one PCI device to another for example?).
I’m sure that other ideas can be found and this problem can be circumvented. Unfortunately, as I said before, I don’t have time of my own to pursue this further, so perhaps someone else will.
Update from five months later: Well, I’m glad I delayed posting this since I actually see a different solution now. Thanks to Intel’s own CVE 2019-0090 whitepaper available here : https://www.intel.com/content/dam/www/public/us/en/security-advisory/documents/cve-2019-0090-whitepaper.pdf
On page 5, you’ll find this diagram that shows how the CSME sits between the CPU and USB and can communicate with it via the Sideband Fabric.
They also explain how the CSME takes care of loading FW onto the various IPs and it controls the IOMMU unit which checks for the SAI authorization. The CVE is about an exploit where someone could write to the ME’s SRAM before IOMMU is enabled, because SAI is not checked while IOMMU is disabled.

So, my new idea would be : Can we disable IOMMU? Since the ME controls it and is the one to enable it, then we should be able to disable it, then we would get to ignore SAI and get full access to the xHCI on Skylake without having to use a different method than what I have already built.
This also tells me that at some point, the ME does have access to it, then writes the firmware to it, then locks things up, so we could also try to find where it does that and patch that code to prevent it from happening. This is kind of like my alternate solution #1 above, but this new information seems to indicate that it’s the ME that handles it, and in the RBE module as well.
Let’s do this!
Alright, enough rambling. Let’s go ahead and get you all to reproduce what I did with step by step instructions.
Step 1 – Hardware setup
That’s easy, you first need to enable the exploit and get code execution with OpenIPC working for your machine. Either using the IntelTXE PoC code from PT if you’re using Apollolake, or using my instructions from my previous articles if on Skylake or Kabylake.
Step 2 – Software Setup
This should also be easy, you mostly need to have Intel System Studio installed and patched as explained in the IntelTXE PoC repository or my previous articles. Then get my ipclib code and import it into your ipython console with from ipclib import *
Step 3 – USB Listing (Apollolake)
If you’re on Apollolake, we can read/write to all the registers, and the xhci implementation I wrote is in the xhci object. You can poke at it in different ways, but to disrupt USB while the system is booted, in ipython ipc console, simply call :
xhci.reset()
To setup USB, reset ports and set addresses to the USB devices :
xhci.setup()
It should list the ports that are in use and show if they are USB 2 or USB 3 devices, though that’s the extent of it as the implementation was never finished.
Step 3 – USB Reset (Skylake/Kabylake)
If you are on Skylake or Kabylake, we can only write, but not read any of the registers, so using the xhci object’s methods will not work here as most of them try to read the status registers.
We can however do this simple write command :
xhci.bar_write32(0x80, 0x2)
which will enable the reset bit on the command register. This will reset the USB controller and prevent the OS from accessing devices. This means that your keyboard and mouse on the target machine will stop working immediately after doing that command, proving it works.
A little extra mischief
As I’ve poked at all sorts of PCI devices during my testing, I also did manage to disrupt the SATA controller when I wanted to. It’s the same principle as with USB though there is no SATA object to use.
The following commands should disable the SATA controller on Apollolake :
addr, _ = setup_sideband_channel(0x150100b5, rs=0, fid=0x90)
t.mem(phys(addr + 4), 4, 1)And here is the command to use on Skylake and Kabylake, using the correct Sideband channel :
addr, _ = setup_sideband_channel(0x150100d9, rs=0, fid=0xb8)
t.mem(phys(addr + 4), 4, 1)You can test it by booting the machine onto a linux system and doing dd if=/dev/sda bs=256 count=1 | hexdump -C to verify that the SATA device can be read (assuming /dev/sda is a SATA drive), then doing it again after running that command through JTAG to confirm that you get an Input/Output error.
If you’re looking for an explanation, then here’s what the command does :
In the case of kabylake, the fid=0xb8 is the function id where bits [7:3] are the PCI device id, and bits [2:0] are the function id, so 0xb8 means PCI device 23.0 which is the SATA device. The rootspace is 0 meaning the main CPU root space, and the sideband channel 0x150100d9 means :
bit 28 : posted (for writes)
bits 27-24: bar 5 (AHCI)
bits 23-16: write opcode 1 : WriteBar
bits 15-8: read opcode 0 : ReadBar
bits 7-0: Port ID 0xD9
Writing at the address + 4 is the AHCI register control, and writing bit 0 to 1 means reset controller.
As “simple” as that.
Conclusion
That’s it! That was the last of my series of articles. I’m sure there’s a lot more stuff I could write about on how I got to that point, but it’s all very tedious and boring (the proof that it’s boring is that I don’t remember most of it). You can probably figure some of the stuff out from the ipclib code that is in there.
I unfortunately never got around to doing my ‘antivirus-immune keylogger’, but it’s not impossible. It turned out that it needed a lot more work than I originally thought it would, and I blame it all on Intel for not providing documentation. I’m sure it could have been done in one week if I didn’t have to spend a year trying to understand how any of the underlying architecture works.
I’m sure there are a lot of other useful applications that can be done by running your own code in the ME. I’ve only done it using IPC scripts, but it should be possible to run binary executables (I know that PT did in their original exploit).
This whole experience was fun. More complex than I ever thought it would be, but still, a lot of fun. It also shows how dangerous the ME can be if someone hijacks it to run their own malicious firmware on it. The possibilities of having ME-viruses are huge, and it shows the importance of having good security and locking access to your flash chips if possible.
With this last article, I close the saga of the Intel ME reverse engineering and security research I’ve done in the last couple of years. I might still poke at it at some point, but I’m concentrating on other stuff for now, with my new business building a hosting service for D&D games being the focus of all my work. I hope the ipclib release I’m doing as well as these articles will be interesting to others and you’ll find something useful in it and perhaps it will inspire others to poke at things that weren’t really meant to be poked at.
It was fun, thanks for reading, and considering everything that’s happening in the world, stay safe!